
Mastering Text Data with Unstructured: Your Comprehensive Guide to ETL Optimization for RAG Systems


With the rapid evolution of AI and its increasing integration into business processes, selecting the right tools to extract, transform, and load (ETL) textual data from documents has never been more critical. As businesses race to leverage Large Language Models (LLMs) like ChatGPT for creating enterprise applications tailored to their specific needs, the challenge lies in the inherent diversity of private data formats. Greggory Elias, CEO of Skim AI, emphasizes in his AI & You's newsletter the significance of this undertaking, noting that companies are exploring ways to build applications on LLMs to address unique organizational challenges. The variability in document types—from simple flat text to complex structures with sections, subsections, and mixed media like text, data, and tables—demands robust ETL pipelines. These pipelines are pivotal for ensuring that data is rendered comprehensible to LLMs, which is a cornerstone for the efficacy of retrieval augmented generative (RAG) systems. The quality and comprehensibility of the data directly influences the performance of RAG systems, making the choice of ETL tools a foundational decision for AI engineers aiming to transition from experimental to production-ready RAG applications.
This backdrop of innovation is set against a broader landscape where the global AI market is experiencing explosive growth, valued at $150.2 billion with projections soaring to $407 billion by 2027. With an anticipated annual growth rate of 37.3% from 2023 to 2030, and 64% of businesses confident in AI's potential to enhance productivity, the urgency for adopting efficient ETL processes is clear.
This article is all about how to use Unstructured for text documents pre-processing, especially for making RAG systems work better. Previously, I talked about another tool, LLM Sherpa, and how it helps pull out different sections from the RAG paper. If you haven't yet, you might want to read that first here.
Today, though, we're diving into what Unstructured can do. I'll walk you through its main features for document partitioning, text cleaning, and content extraction, mainly focusing on PDF documents. However, everything we will discuss applies to other types of documents with few to no changes. I will conclude by laying out few points that will help you decide if this tool is ideal for you ETL case scenario for your RAG application. We'll look closely at how Unstructured helps in pulling important information from texts, making your data more useful and your work more efficient.
Before our dive, let us go through the 7 stages of the RAG workflow:
Data Ingestion: Begin by gathering data from various sources. This initial step is crucial for setting up a solid foundation for the RAG system.
Data Preprocessing and Cleaning: After data collection, it's important to refine the dataset by removing irrelevant or unnecessary information, ensuring the quality of the data for processing.
Chunking: Divide the textual data into manageable segments. This process facilitates more efficient processing by breaking down large texts into smaller, more digestible pieces.
Embedding: Convert the text segments into numerical vectors. This step translates textual information into a format that can be understood and utilized by machine learning models.
Vector Database Storage: Choose an appropriate storage solution for the processed vectors. The selection of a vector database is critical for efficient retrieval and management of the data embeddings.
User Prompt Processing: Process user queries by identifying and retrieving the most relevant data segments from the vector database through similarity matching.
LLM Response Generation: Combine the retrieved data segments with the original user query, and feed this information into the LLM. This final step leverages the combined data to generate a precise and contextually relevant response.
In this article, we are ultimately interested in optimizing step number 2.
Unstructured
Unstructured.io offers both a platform and an open source API to perform ETL over unstructured data aimed at optimizing enterprise level retrieval augmented generative architectures. Their SaaS API platform solution comes equipped with powerful models and functionalities that provide a no-code tool that handles all of the RAG flow steps mentioned above, providing the user with:
Data sources connectors such as AWS S3, Azure blob storage, and Google Cloud Storage alongside others.
Data transformation pipelines covering natural language extraction, document partitioning and structuring,
Data cleaning
Data chunking
Embeddings generation
Data Destination connectors to allow streaming processed documents into databases including vector indices.
Platform pricing
The platform offers the following plans:
free trial with a $100 worth of credits to test the platform's features
Pay-as-you-go model with a pay by the hour scheme
A monthly subscription scheme best suitable for small to medium sized enterprises.
Customer hosted for larger companies with on premise deployment.
Unstructured Core Library
For developers, unstructured offers the Unstructured core library, which is an open-source toolkit designed to significantly streamline the process of ingesting, processing, and pre-processing images and text documents. It facilitates the transformation of unstructured data from formats like PDFs, HTML, Word documents, and more into structured outputs that are ready for further analysis or processing by Large Language Models (LLMs). This library is particularly valuable for tasks such as Retrieval Augmented Generation (RAG), where the quality and structure of input data can greatly influence the performance and accuracy of generated outputs.
Key Uses and Capabilities:
Partitioning: Divides documents into structured formats like JSON or CSV, making raw data more accessible and manageable for analysis.
Cleaning: Offers functionalities to remove unwanted or irrelevant content from documents, ensuring that the data fed into LLMs or other processing stages is of high quality.
Extracting: Enables the extraction of specific content from documents, supporting a wide range of use cases from data analysis to feeding processed data into machine learning models.
Staging: Prepares data for downstream applications, whether it be for machine learning inference, data labeling, or other specialized processes.
Chunking: Facilitates the breaking down of partitioned documents into smaller sections, optimizing them for RAG applications and enhancing the efficiency of similarity searches.
Supported Document Types: The library is versatile, supporting a wide array of document types, including but not limited to PDFs, HTML files, Word documents, and more. This extensive compatibility makes it an excellent tool for organizations dealing with a variety of document formats in their data processing workflows.
Installation
Installing the Unstructured library is straightforward. For comprehensive support of all document types, you can use the Python package manager pip:
pip install "unstructured[all-docs]"
For basic needs, such as handling plain text files, HTML, XML, JSON, and Emails without extra dependencies:
pip install unstructured
For specialized document types, additional dependencies can be installed as needed, for example:
pip install "unstructured[docx,pptx,pdf]"
Partitioning
After installation, getting started with document partitioning and extraction is simple. The library provides a partition function that intelligently routes documents to the appropriate processing function based on file type, simplifying the initial steps of data processing:
from unstructured.partition.auto import partition
# For parsing a document
elements = partition(filename="path/to/your/document.pdf")
This function call will partition the document into structured elements, ready for further processing or analysis. These elements can be any of the following types:
FigureCaptionNarrativeTextListItemTitleAddressTablePageBreakHeaderFooterUncategorizedTextImageFormula
We can easily view these elements as a list of dictionaries each representing an extracted document element using the convert_to_dict function:
from unstructured.staging.base import convert_to_dict
output_dict = convert_to_dict(elements)
And this is the output:


Text Cleaning
The Unstructured core library significantly enhances the preprocessing workflow for NLP models by offering advanced data cleaning functionalities. These are designed to remove or alter unwanted content, ensuring that the output is optimized for downstream tasks.
Main Cleaning Functions:
bytes_string_to_string: Converts byte-like strings to regular strings, addressing encoding issues that may arise during document processing.clean: A versatile cleaning function that can be configured to remove bullets, excess whitespace, dashes, and trailing punctuation, with an option to lowercase the entire text.clean_bullets: Targets and removes bullet points from the beginning of text, aiding in the normalization of list items or bullet-pointed information.clean_dashes: Eliminates dashes and similar punctuation from text, useful for creating uniformity in hyphenated words or phrases.clean_extra_whitespace: Removes unnecessary spaces, tabs, and newline characters, ensuring text consistency and readability.clean_non_ascii_chars: Strips out non-ASCII characters from the text, making it suitable for systems or processes that require standard ASCII input.
We can combine these functions to build a complete text cleaning pipeline:
from unstructured.cleaners.core import (
bytes_string_to_string,
clean,
clean_bullets,
clean_dashes,
clean_extra_whitespace,
clean_non_ascii_chars,
)
# Initial unclean text
unclean_text = "● ITEM 1A: SECTION ELEMENTS—\x88This section contains ð\x9f\x98\x80non-ascii characters! And unnecessary whitespace."
# Apply cleaning functions
text_cleaned_bullets = clean_bullets(unclean_text)
text_cleaned_non_ascii = clean_non_ascii_chars(text_cleaned_bullets)
text_cleaned_bytes = bytes_string_to_string(text_cleaned_non_ascii, encoding="utf-8")
text_cleaned_dashes = clean_dashes(text_cleaned_bytes)
text_cleaned_whitespace = clean_extra_whitespace(text_cleaned_dashes)
# # Final clean text
clean_text = clean(text_cleaned_non_ascii, trailing_punctuation=True, lowercase=True)
print(clean_text)

The order in which you apply cleaning functions can significantly affect the outcome and the successful execution of your code, particularly when dealing with various encodings and character representations in text. Here's why the sequence you've chosen works:
clean_bulletsFirst: Starting withclean_bulletsmakes sense as it directly removes bullet points from the start of your text. This operation is straightforward and does not depend on the text's encoding or the presence of special characters elsewhere in the string.clean_non_ascii_charsNext: After removing bullets, you next remove non-ASCII characters. This step is crucial before attempting any encoding conversions (such as bytes to string) because it directly eliminates characters that could cause encoding errors or that are not representable in your target encoding (UTF-8). By doing this early, you reduce the risk of encountering byte range errors when you later attempt to handle byte-like strings.bytes_string_to_stringAfter Non-ASCII Cleaning: By placingbytes_string_to_stringafterclean_non_ascii_chars, you ensure that the most problematic characters (those outside the ASCII range) are already dealt with. This reduces the complexity forbytes_string_to_string, as it now primarily deals with converting properly encoded byte-like strings to UTF-8, without having to worry about non-ASCII characters causing issues.clean_dashesandclean_extra_whitespace: These functions are applied after the encoding-related cleanings. Cleaning dashes and extra whitespace usually doesn't involve encoding issues, so it's safer to do these operations once the text is already in a more consistent and clean state encoding-wise.Final
cleanCall: The final use ofcleanwith multiple parameters ensures a broad cleanup based on the flags you've provided. This step is more about general text cleanup and formatting rather than addressing encoding or specific character issues.
Content Extraction
Now that we have learned how to clean our data with Unstructured' s functions, extracting specific elements from text data is a next crucial step. The Unstructured core library provides a robust set of functions designed for this purpose, enabling users to pinpoint and extract valuable pieces of information embedded within text. These functions range from extracting dates, email addresses, and IP addresses to more specialized tasks like identifying MAPI IDs and alphanumeric bullets. Here’s an overview of these key extraction functions and what they're designed for:
extract_datetimetz: Extracts dates, times, and time zones from strings, particularly useful in processing email headers.extract_email_address: Identifies and extracts email addresses from text, returning them in a list.extract_ip_address: Pulls both IPv4 and IPv6 addresses from the text, useful for logs and network-related documents.extract_ip_address_name: Focuses on extracting the names associated with IP addresses in email headers.extract_mapi_id: Extracts MAPI IDs from email headers, aiding in email processing and analysis.extract_ordered_bullets: Identifies and extracts alphanumeric bullets, assisting in the organization and structure of lists within texts.extract_text_after/extract_text_before: These functions are pivotal for retrieving text segments relative to specific patterns, enhancing text parsing capabilities.extract_us_phone_number: Isolates US phone numbers from text, offering utility in data extraction from contact information.group_broken_paragraphs: Groups together broken paragraphs, which is particularly useful for text normalization in poorly formatted documents.remove_punctuation/replace_unicode_quotes: While primarily cleaning functions, they play a critical role in preparing text for extraction by removing noise.translate_text: Translates text between languages using machine translation models, expanding the accessibility of text data across languages.
Let's apply a combination of these functions on a sample text that contains a variety of elements we wish to extract:
from unstructured.cleaners.extract import (
extract_datetimetz,
extract_email_address,
extract_ip_address,
extract_ip_address_name,
extract_mapi_id,
extract_ordered_bullets,
extract_text_after,
extract_us_phone_number
)
# Sample text
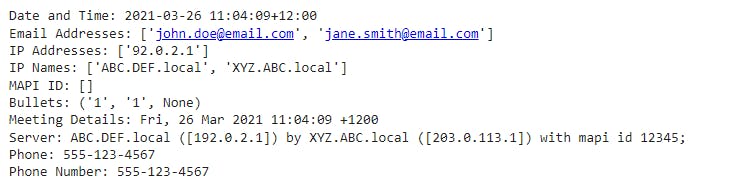
text = """
1.1 Important meeting points: The big brown fox jumps over the lazy dog.
Contact: John Doe <john.doe@email.com>, Jane Smith <jane.smith@email.com>
Meeting Time: Fri, 26 Mar 2021 11:04:09 +1200
Server: ABC.DEF.local ([192.0.2.1]) by XYZ.ABC.local ([203.0.113.1]) with mapi id 12345;
Phone: 555-123-4567
"""
# Extracting elements
date_time = extract_datetimetz(text)
emails = extract_email_address(text)
ip_addresses = extract_ip_address(text)
ip_names = extract_ip_address_name(text)
mapi_id = extract_mapi_id(text)
bullets = extract_ordered_bullets("1.1 Important point")
meeting_details = extract_text_after(text, r"Meeting Time:")
phone_number = extract_us_phone_number(text)
print(f"Date and Time: {date_time}")
print(f"Email Addresses: {emails}")
print(f"IP Addresses: {ip_addresses}")
print(f"IP Names: {ip_names}")
print(f"MAPI ID: {mapi_id}")
print(f"Bullets: {bullets}")
print(f"Meeting Details: {meeting_details.strip()}")
print(f"Phone Number: {phone_number}")
By combining all of these methods, you can go from having a document with complex elements to having the same elements cleaned and stored to build an optimal text-based knowledge base. You can view Unstructured' s full documentation here.
Should you use Unstructured in your RAG pipeline?
As we wrap up our exploration of Unstructured' s capabilities for ETL processes, it's important to pinpoint when this tool is ideal for your projects and when you might need to consider alternatives. Unstructured shines in a variety of scenarios due to its robust features for cleaning, extracting, and processing textual data. However, its utility can vary depending on the specific needs of your RAG system or the nature of your documents. Here are some considerations to help you decide if Unstructured is right for you:
Ideal Use Cases for Unstructured:
Complex Document Processing: Unstructured is exceptionally well-suited for handling documents that are rich in text but also contain complex elements like images, formulas, and unstructured layouts. Its parsing capabilities make it a powerful tool for extracting valuable data from such documents.
Data Cleaning and Extraction: If your primary need involves deep cleaning of textual data—removing unwanted characters, standardizing formats, or extracting specific information—Unstructured offers a comprehensive suite of functionalities tailored for these tasks.
Highly Customizable ETL Pipelines: For projects requiring flexible and customizable ETL pipelines that can adapt to various data types and processing requirements, Unstructured' s open-source nature allows for significant customization and integration into existing systems.
When Unstructured May Not Be the Best Fit:
Graph Knowledge Base Creation: If your goal is to build a graph knowledge base with intricate relationships between document sections and subsections, Unstructured might not be the ideal choice. Tools like LLM Sherpa offer direct access to a document's sections, making them better suited for this specific purpose.
Simplified Document Handling Needs: For projects that involve straightforward text documents without the need for complex extraction or cleaning processes, simpler tools might suffice. In such cases, the extensive capabilities of Unstructured could be more than what's necessary.
Integration and Workflow Compatibility: Assess how seamlessly Unstructured can be woven into your current workflows. Its flexibility through API and library features demands consideration of integration efforts.
Model Management: The employment of advanced models for features like table extraction underscores the need for effective model management. This includes considerations for model selection, integration complexities, and ongoing maintenance to ensure that the extraction capabilities remain reliable and up-to-date.
Conclusion
As AI continues to shape business processes, selecting the right ETL tools like Unstructured becomes crucial for effectively handling textual data. Unstructured, with its powerful document processing capabilities, stands out for tasks involving complex PDFs, data cleaning, and information extraction, making it a go-to for those looking to leverage Large Language Models (LLMs) like ChatGPT.
Yet, it's not a one-size-fits-all solution. The choice to use Unstructured should be guided by the specific needs of your project, the complexity of your documents, and how well it integrates into your existing systems. Its advanced model use for table extraction, for example, requires thoughtful integration and might suggest alternative solutions for simpler needs or specific graph knowledge base constructions.
In wrapping up, Unstructured presents a compelling option for enhancing ETL processes, ready to transform your unstructured data into structured insights. But as you consider integrating such powerful tools into your workflow, ask yourself: How can Unstructured or similar technologies elevate your current data handling processes to unlock new possibilities for your business or research?